據(jù)中")
MySQL數(shù)據(jù)庫InnoDB數(shù)據(jù)恢復工具的使用小結詳解建站
導讀:1建站知識本文從實際使用經(jīng)驗出發(fā),介紹一款開源的MySQL數(shù)據(jù)庫InnoDB數(shù)據(jù)恢復工具:innodb-tools,它通過從原始數(shù)據(jù)文件中提取表的行記錄,實現(xiàn)從丟失的或者seo網(wǎng)站優(yōu)化軟件seo網(wǎng)站關鍵詞優(yōu)化。
 本文從實際使用經(jīng)驗出發(fā),介紹一款開源的MySQL數(shù)據(jù)庫InnoDB數(shù)據(jù)恢復工具:innodb-tools,它通過從原始數(shù)據(jù)文件中提取表的行記錄,實現(xiàn)從丟失的或者被毀壞的MySQL表中恢復數(shù)據(jù)。例如,當你不小心執(zhí)行DROP TABLE、TRUNCATE TABLE或者DROP DATABASE之后,可以通過以下方式恢復數(shù)據(jù)。
以下內(nèi)容大部分參考自:Percona 如何seo優(yōu)化推廣網(wǎng)站Data Recovery Tool for InnoDB,文檔是英文的,而且寫的比較晦澀,這里是個人的實戰(zhàn)經(jīng)驗總結,供大家參考學習。
在介紹innodseo網(wǎng)站優(yōu)化b-tools工具進行數(shù)據(jù)恢復之前,首先明確以下幾點:
1、這個工具只能對InnoDB/XtraDB表有效,而無法恢復MyISAM表(注: Percona號稱有一套用于恢復MyISAM表的工具,但是本人未做嘗試)。
2、這個工具是以保存的MySQL數(shù)據(jù)文件進行恢復的,而不用MySQL Server運行。
3、不能保證數(shù)據(jù)總一定可被恢復。例如,被重寫的數(shù)據(jù)不能被恢復,這種情況下可能需要針對系統(tǒng)或物理的方式來恢復,不屬于本工具的范疇。
4、恢復的最好時機是當你發(fā)現(xiàn)數(shù)據(jù)丟失時,盡快備份MySQL數(shù)據(jù)文件。
5、使用這個工具需要手動做一些工作,并不是全自動完成的。
6、恢復過程依賴于你對丟失數(shù)據(jù)的了解程度,在恢復過程中可能需要在不同版本的數(shù)據(jù)之間做出選擇。那么如果你越了解自己的數(shù)據(jù),恢復的可能性就越大。
接下來,下面通過一個例子來介紹如何通過這個工具進行恢復。
1. 前提條件
首先,需要理解的是innodb-tools工具不是通過連接到在線的database進行數(shù)據(jù)恢復,而是通過離線拷貝數(shù)據(jù)的方式進行的。注意:不要在MySQL運行的時候,直接拷貝InnoDB文件,這樣是不安全的,會影響數(shù)據(jù)恢復過程。
為了完成數(shù)據(jù)恢復,必須知道將要被恢復的表結構(列名、數(shù)據(jù)類型)。最簡單的方式就是SHOW CREATE TABLE,當然后續(xù)會介紹幾種可替代的方式。因此,如果有一個MySQL server作為備份,即使數(shù)據(jù)是很早的甚至表中沒有記錄,可以有助于使用innodb-tools工具進行恢復。不過這個不是必須的。
2. 簡單例子
復制代碼 代碼如下:
mysql> TRUNCATE TABLE customer;
3. 構建工具
為了構建innodb-tools工具,需要依賴于C編譯器、make工具等。
1、下載解壓innodb-tools工具源碼:
復制代碼 代碼如下:
wget https://launchpad.net/percona-data-recovery-tool-for-innodb/trunk/release-0.5/+download/percona-data-recovery-tool-for-innodb-0.5.tar.gztar -zxvf percona-data-recovery-tool-for-innodb-0.5.tar.gz
2、進入解壓后根目錄下的myseo網(wǎng)站關鍵詞優(yōu)化sql-source目錄,運行配置命令(注:不運行make命令):
復制代碼 代碼如下:
cd percona-data-recovery-tool-for-innodb-0.5/mysql-source
./configure
3、完成配置步驟后,回到解壓后的根目錄,運行make命令,編譯生成page_parser和constraints_parser工具:
復制代碼 代碼如下:
cd ..
make
page_parser工具將根據(jù)InnoDB的底層實現(xiàn)原理,解析表的頁和行結構。constraints_parser工具暫時不使用,后續(xù)還需要在定義表結構之后,重新編譯生成它。
如果編譯過程中出現(xiàn)問題,點擊這里。本文使用過程中沒有出現(xiàn)問題,故不再一一列舉。
4. 提取需要的頁
InnoDB頁的默認大小是16K,每個頁屬于一個特定表中的一個特定的index。page_parser工具通過讀取數(shù)據(jù)文件,根據(jù)頁頭中的index ID,拷貝每個頁到一個單獨的文件中。
如果你的MySQL server被配置為innodb_file_per_table=1,那么系統(tǒng)已經(jīng)幫你實現(xiàn)上述過程。所有需要的頁都在.ibd文件,而且通常你不需要再切分它。然而,如果.ibd文件中可能包含多個index,那么將頁單獨切分開還是有必要的。如果MySQL server沒有配置innodb_file_per_table,那么數(shù)據(jù)會被保存在一個全局的表命名空間(通常是一個名為ibdata1的文件,本文屬于這種情況),這時候就需要按頁對文件進行切分。
4.1 切分頁
運行page_parser工具進行切分:
•如果MySQL是5.0之前的版本,InnoDB采取的是REDUNDANT格式,運行以下命令:
復制代碼 代碼如下:
./page_parser -4 -f /path/to/ibdata1
•如果MySQL是5.0版本,InnoDB采取的是COMPACT格式,運行以下命令:
復制代碼 代碼如下:
./page_parser -5 -f /path/to/ibdata1
運行后,page_parser工具會創(chuàng)建一個pages-<TIMESTAMP>的目錄,其中TIMESTAMP是UNIX系統(tǒng)時間戳。在這個目錄下,為每個index ID,以頁的index ID創(chuàng)建一個子目錄。例如:
復制代碼 代碼如下:
pages-1330842944/FIL_PAGE_INDEX/0-1/1-00000008.page
pages-1330842944/FIL_PAGE_INDEX/0-1/6-00000008.page
4.2 選擇需要的Index ID
一般來說,我們需要根據(jù)表的主鍵(PRIMARY index)進行恢復,主鍵中包含了所有的行。以下是一些可以實現(xiàn)的步驟:
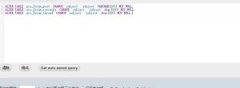
如果數(shù)據(jù)庫仍處于運行狀態(tài),并且表沒有被drop掉,那么可以啟動InnoDB Tablespace Monitor,輸出所有表和indexes,index IDs到MySQL server的錯誤日志文件。創(chuàng)建innodb_table_monitor表用于收集innodb存儲引擎表及其索引的存儲方式:
復制代碼 代碼如下:
相關seo網(wǎng)站優(yōu)化軟件seo網(wǎng)站關鍵詞優(yōu)化。
本文從實際使用經(jīng)驗出發(fā),介紹一款開源的MySQL數(shù)據(jù)庫InnoDB數(shù)據(jù)恢復工具:innodb-tools,它通過從原始數(shù)據(jù)文件中提取表的行記錄,實現(xiàn)從丟失的或者被毀壞的MySQL表中恢復數(shù)據(jù)。例如,當你不小心執(zhí)行DROP TABLE、TRUNCATE TABLE或者DROP DATABASE之后,可以通過以下方式恢復數(shù)據(jù)。
以下內(nèi)容大部分參考自:Percona 如何seo優(yōu)化推廣網(wǎng)站Data Recovery Tool for InnoDB,文檔是英文的,而且寫的比較晦澀,這里是個人的實戰(zhàn)經(jīng)驗總結,供大家參考學習。
在介紹innodseo網(wǎng)站優(yōu)化b-tools工具進行數(shù)據(jù)恢復之前,首先明確以下幾點:
1、這個工具只能對InnoDB/XtraDB表有效,而無法恢復MyISAM表(注: Percona號稱有一套用于恢復MyISAM表的工具,但是本人未做嘗試)。
2、這個工具是以保存的MySQL數(shù)據(jù)文件進行恢復的,而不用MySQL Server運行。
3、不能保證數(shù)據(jù)總一定可被恢復。例如,被重寫的數(shù)據(jù)不能被恢復,這種情況下可能需要針對系統(tǒng)或物理的方式來恢復,不屬于本工具的范疇。
4、恢復的最好時機是當你發(fā)現(xiàn)數(shù)據(jù)丟失時,盡快備份MySQL數(shù)據(jù)文件。
5、使用這個工具需要手動做一些工作,并不是全自動完成的。
6、恢復過程依賴于你對丟失數(shù)據(jù)的了解程度,在恢復過程中可能需要在不同版本的數(shù)據(jù)之間做出選擇。那么如果你越了解自己的數(shù)據(jù),恢復的可能性就越大。
接下來,下面通過一個例子來介紹如何通過這個工具進行恢復。
1. 前提條件
首先,需要理解的是innodb-tools工具不是通過連接到在線的database進行數(shù)據(jù)恢復,而是通過離線拷貝數(shù)據(jù)的方式進行的。注意:不要在MySQL運行的時候,直接拷貝InnoDB文件,這樣是不安全的,會影響數(shù)據(jù)恢復過程。
為了完成數(shù)據(jù)恢復,必須知道將要被恢復的表結構(列名、數(shù)據(jù)類型)。最簡單的方式就是SHOW CREATE TABLE,當然后續(xù)會介紹幾種可替代的方式。因此,如果有一個MySQL server作為備份,即使數(shù)據(jù)是很早的甚至表中沒有記錄,可以有助于使用innodb-tools工具進行恢復。不過這個不是必須的。
2. 簡單例子
復制代碼 代碼如下:
mysql> TRUNCATE TABLE customer;
3. 構建工具
為了構建innodb-tools工具,需要依賴于C編譯器、make工具等。
1、下載解壓innodb-tools工具源碼:
復制代碼 代碼如下:
wget https://launchpad.net/percona-data-recovery-tool-for-innodb/trunk/release-0.5/+download/percona-data-recovery-tool-for-innodb-0.5.tar.gztar -zxvf percona-data-recovery-tool-for-innodb-0.5.tar.gz
2、進入解壓后根目錄下的myseo網(wǎng)站關鍵詞優(yōu)化sql-source目錄,運行配置命令(注:不運行make命令):
復制代碼 代碼如下:
cd percona-data-recovery-tool-for-innodb-0.5/mysql-source
./configure
3、完成配置步驟后,回到解壓后的根目錄,運行make命令,編譯生成page_parser和constraints_parser工具:
復制代碼 代碼如下:
cd ..
make
page_parser工具將根據(jù)InnoDB的底層實現(xiàn)原理,解析表的頁和行結構。constraints_parser工具暫時不使用,后續(xù)還需要在定義表結構之后,重新編譯生成它。
如果編譯過程中出現(xiàn)問題,點擊這里。本文使用過程中沒有出現(xiàn)問題,故不再一一列舉。
4. 提取需要的頁
InnoDB頁的默認大小是16K,每個頁屬于一個特定表中的一個特定的index。page_parser工具通過讀取數(shù)據(jù)文件,根據(jù)頁頭中的index ID,拷貝每個頁到一個單獨的文件中。
如果你的MySQL server被配置為innodb_file_per_table=1,那么系統(tǒng)已經(jīng)幫你實現(xiàn)上述過程。所有需要的頁都在.ibd文件,而且通常你不需要再切分它。然而,如果.ibd文件中可能包含多個index,那么將頁單獨切分開還是有必要的。如果MySQL server沒有配置innodb_file_per_table,那么數(shù)據(jù)會被保存在一個全局的表命名空間(通常是一個名為ibdata1的文件,本文屬于這種情況),這時候就需要按頁對文件進行切分。
4.1 切分頁
運行page_parser工具進行切分:
•如果MySQL是5.0之前的版本,InnoDB采取的是REDUNDANT格式,運行以下命令:
復制代碼 代碼如下:
./page_parser -4 -f /path/to/ibdata1
•如果MySQL是5.0版本,InnoDB采取的是COMPACT格式,運行以下命令:
復制代碼 代碼如下:
./page_parser -5 -f /path/to/ibdata1
運行后,page_parser工具會創(chuàng)建一個pages-<TIMESTAMP>的目錄,其中TIMESTAMP是UNIX系統(tǒng)時間戳。在這個目錄下,為每個index ID,以頁的index ID創(chuàng)建一個子目錄。例如:
復制代碼 代碼如下:
pages-1330842944/FIL_PAGE_INDEX/0-1/1-00000008.page
pages-1330842944/FIL_PAGE_INDEX/0-1/6-00000008.page
4.2 選擇需要的Index ID
一般來說,我們需要根據(jù)表的主鍵(PRIMARY index)進行恢復,主鍵中包含了所有的行。以下是一些可以實現(xiàn)的步驟:
如果數(shù)據(jù)庫仍處于運行狀態(tài),并且表沒有被drop掉,那么可以啟動InnoDB Tablespace Monitor,輸出所有表和indexes,index IDs到MySQL server的錯誤日志文件。創(chuàng)建innodb_table_monitor表用于收集innodb存儲引擎表及其索引的存儲方式:
復制代碼 代碼如下:
相關seo網(wǎng)站優(yōu)化軟件seo網(wǎng)站關鍵詞優(yōu)化。
關鍵詞標簽: SQL 小結 數(shù)據(jù)恢復
聲明: 本文由我的SEOUC技術文章主頁發(fā)布于:2023-05-24 ,文章MySQL數(shù)據(jù)庫InnoDB數(shù)據(jù)恢復工具的使用小結詳解建站主要講述小結,數(shù)據(jù)恢復,SQL網(wǎng)站建設源碼以及服務器配置搭建相關技術文章。轉(zhuǎn)載請保留鏈接: http://www.bifwcx.com/article/web_6511.html





登錄入口(校友邦網(wǎng)頁")
")
站模板必做SEO優(yōu)化")
化中網(wǎng)站主題跟內(nèi)容不能偏差")
